The structure learning PC Algorithm is applied on the synthetic ALARM Dataset. This notebook (i) shows the limitations of the algorithm by using an oracle conditional independence test, (ii) showcases the performance with the Chi-squared conditional independence test, and (iii) investigates the dependence on the dataset’s sample size.
1.1 Introduction
This notebook presents and applies the structure learning PC algorithm on the alarm dataset. The PC algorithm was introduced by Spirtes, Glymour, and Scheines (2000) to infer a graphical structure to a distribution. (Conditional) independencies hold in the distribution if paths in the associated graph are blocked (d-separation). The converse statement is called faithfulness. The PC algorithm starts with a complete graph and removes edges by testing (conditional) independencies. The key assumption of the PC algorithm is that all relevant and influencing variables are measures, a.k.a. ’no unmeasured confounding. Directed edges encode causality, a non-symmetric generalization of conditioning.
Spirtes, Peter, Clark N Glymour, and Richard Scheines. 2000. Causation, Prediction, and Search. MIT press.
1.2 Loading the Alarm Dataset and its DAG
We apply the algorithm on the alarm dataset (Beinlich et al. 1989) of size 37 x 20,000. It can be downloaded from the Zenodo ‘Graphical Modelling and Causal Inference’ (https://zenodo.org/records/14793281) community under the CC0 License.
Beinlich, Ingo A, Henri Jacques Suermondt, R Martin Chavez, and Gregory F Cooper. 1989. “The ALARM Monitoring System: A Case Study with Two Probabilistic Inference Techniques for Belief Networks.” In AIME 89: Second European Conference on Artificial Intelligence in Medicine, London, August 29th–31st 1989. Proceedings, 247–56. Springer.
No issues found -- the project is in a consistent state.
# Used packages, only for information.library(zen4R) # download files from Zenodolibrary(bnlearn) # read ground truth graphlibrary(pcalg) # PC Algorithm implementationlibrary(Rgraphviz) # plot graphslibrary(MVN) # multivariate normal test
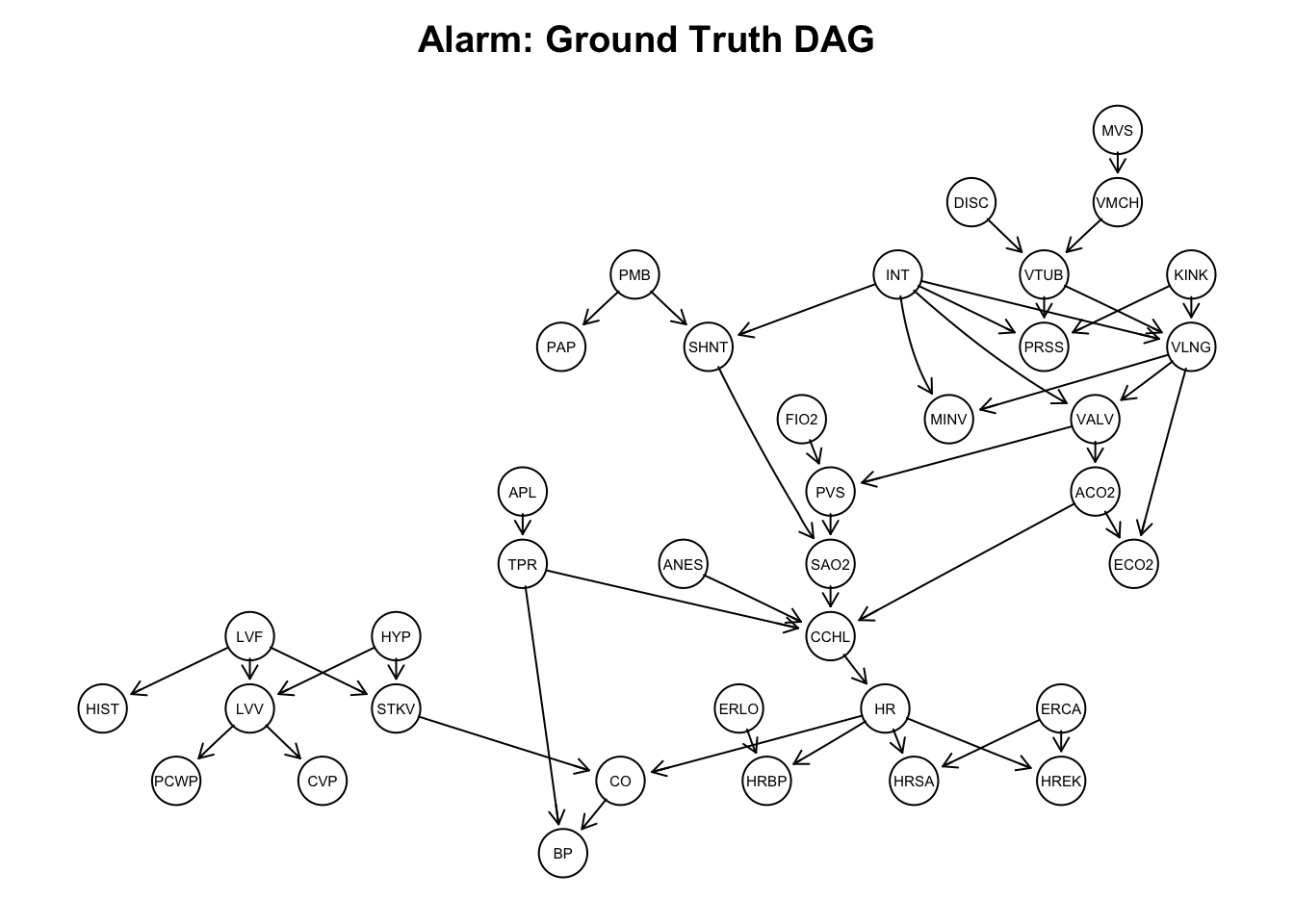
The underlying ground truth directed acyclic graph (DAG) is given in the plot below. It is the DAG visualizing the structural equation model generating the observational dataset. All collumns represent patient measurements and status of clinial treatment machines.
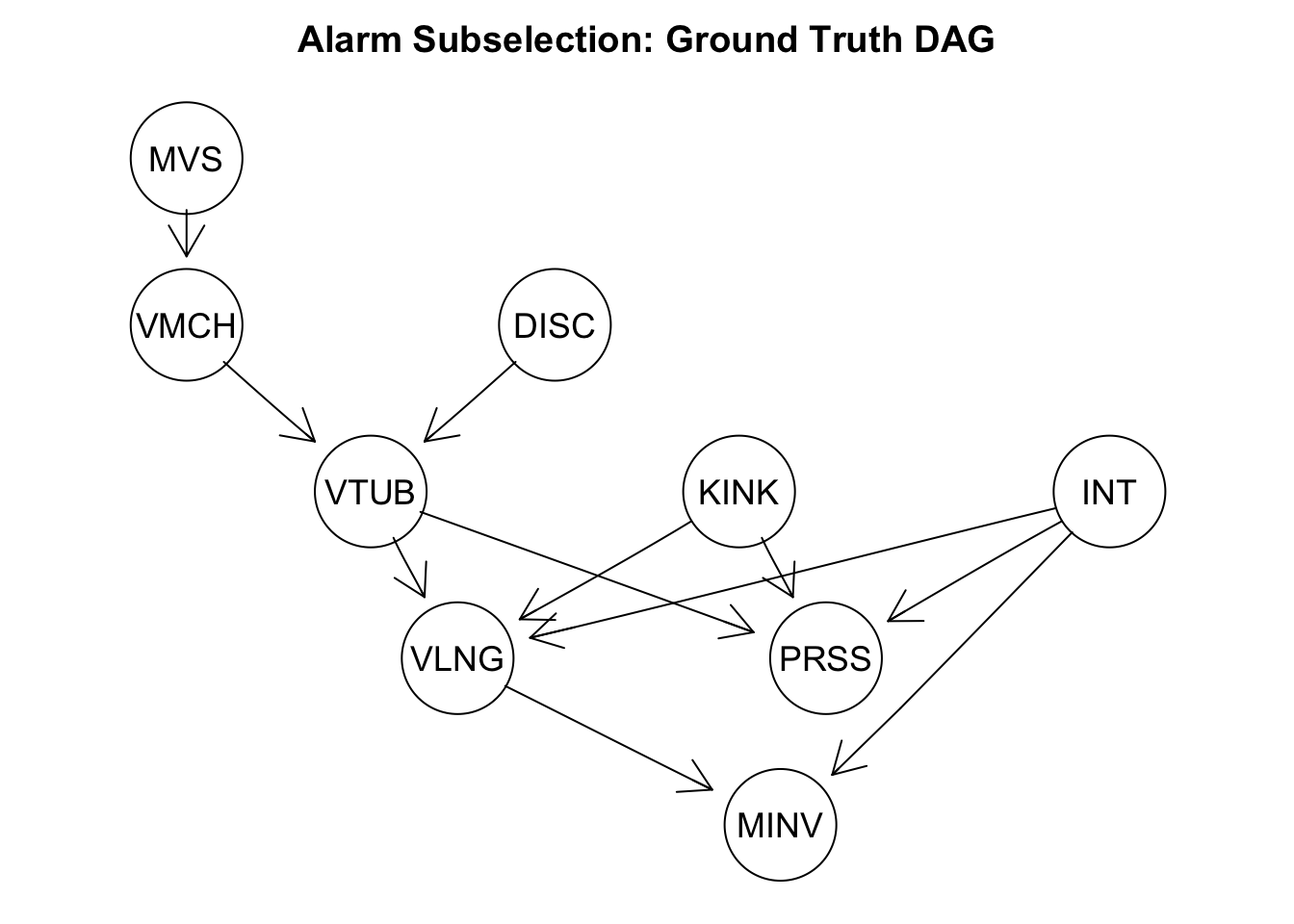
For demonstration purposes, we restrict the dataset to the ancestral set of ‘MINV’. Note that the number of DAGs on n nodes grows super-exponentially (https://oeis.org/A003024) and that there are more than 800 Billion DAGs on 9 node.
1.3 PC Algorithm: Oracle Conditional Independence Test
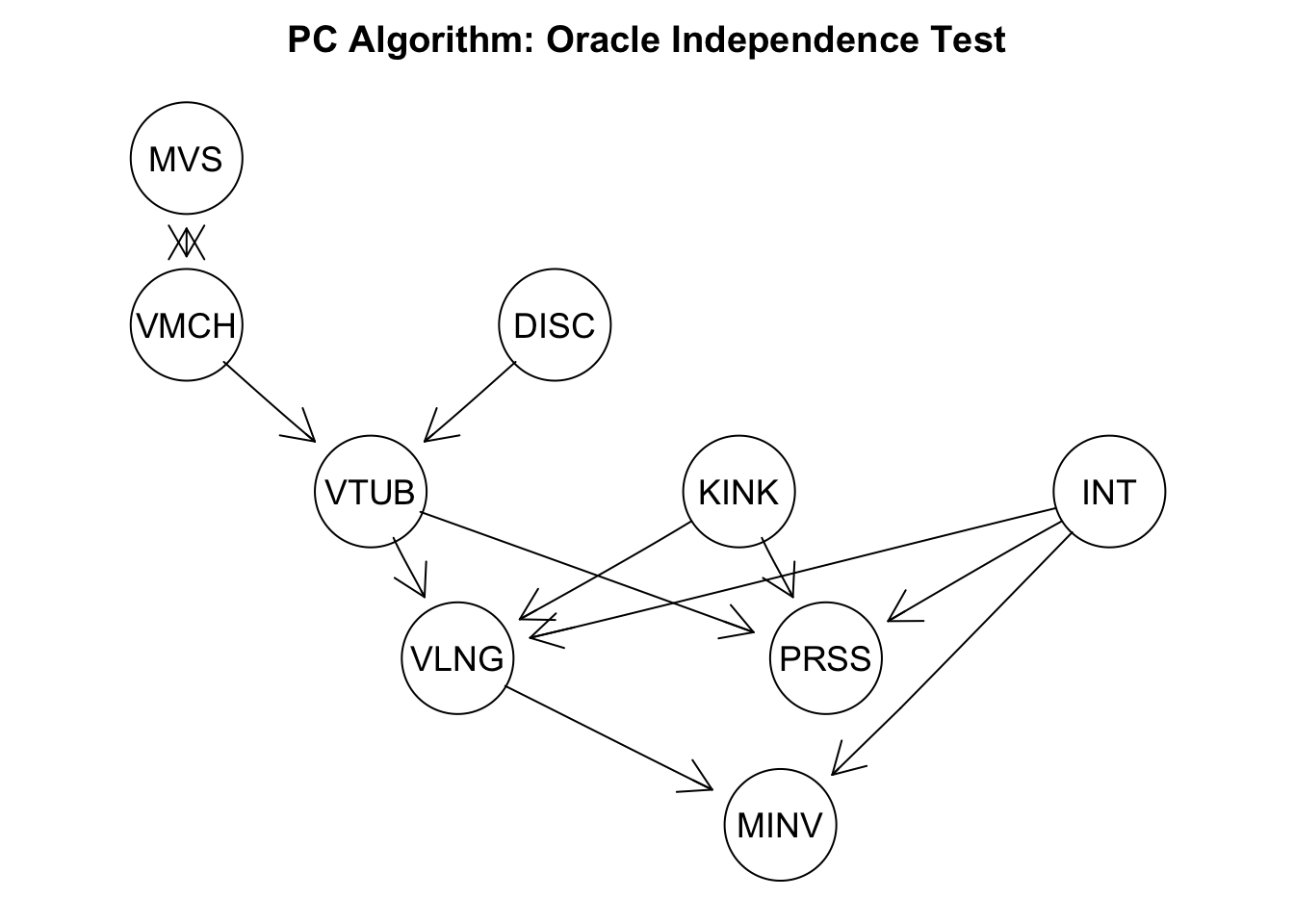
Without further assumptions, it is not possible to identify the presented DAG, which is why the PC algorithm returns a completed partially directed acyclic graph (CPDAG). Each CPDAG represents a class of DAGs where the undirected edges have to be appropriately directed. The following code chunk gives the best possible PC algorithm outcome by taking the implied condition independencies from the graph above instead of testing any hypothesis.
ci_test_dsep <-function(ground_truth, var_names) {function(x, y, S, suffStat) { is_indep <-dsep(var_names[x], var_names[y], var_names[S], ground_truth)return(as.numeric(is_indep)) }}pc_oracle_fit <-pc(suffStat =list(),indepTest =ci_test_dsep(sub_gt, sub_names), alpha =0.5, # irrelevant since ci_test_dsep() returns either 0 or 1labels = sub_names)plot(pc_oracle_fit@graph, main ="PC Algorithm: Oracle Independence Test")
This returned CPDAG is very similar to the ground truth DAG. Only the edge between ‘MVS’ and ‘VMCH’ can not be oriented. One criterion to quantify the distance between CPDAGs is to calculate the 1-norm of the corresponding adjacency matrices.
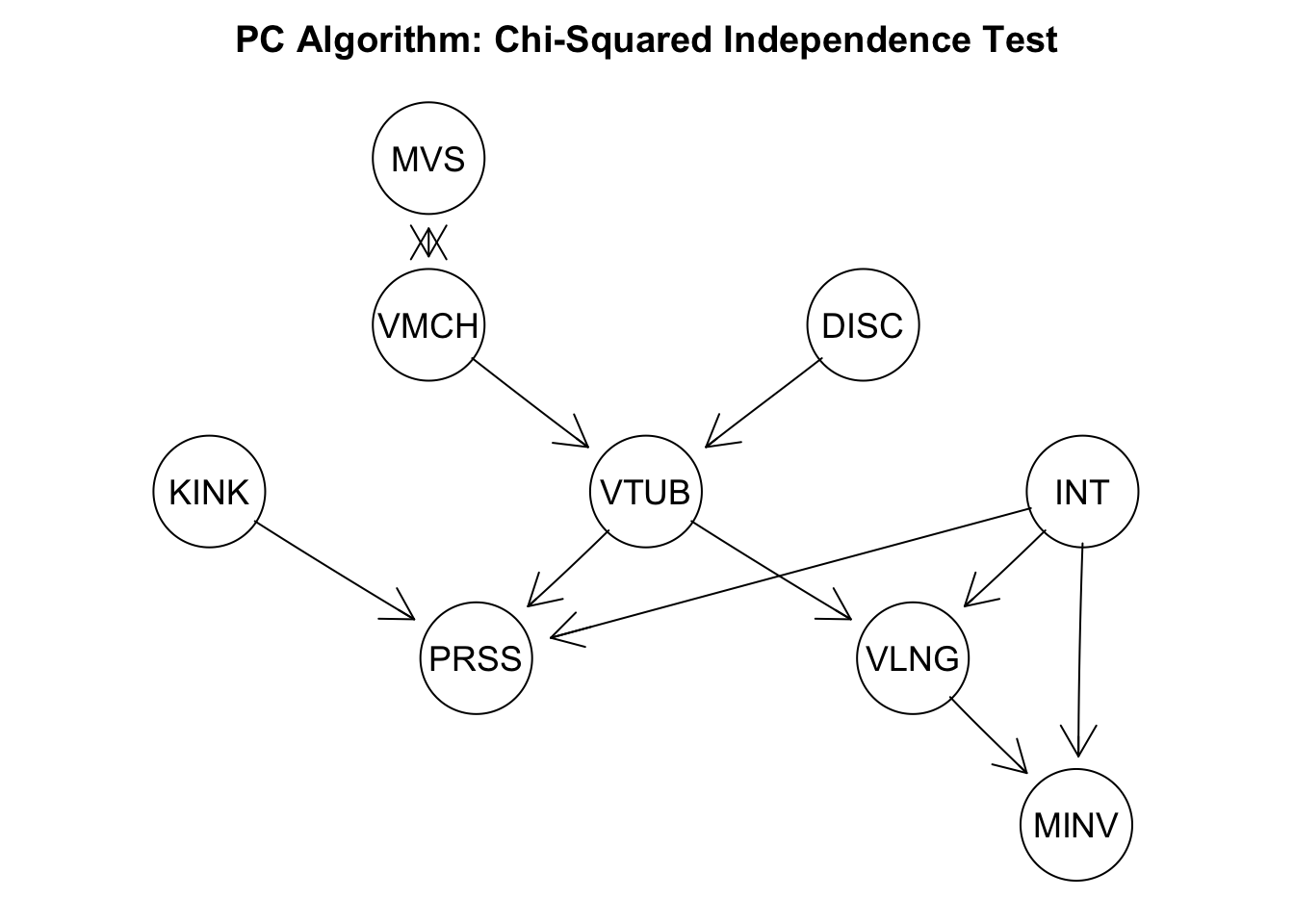
As our data is discrete with at most 4 levels, we choose the Chi-Squared independence test as the criterion to remove edges with the PC algorithm. Any rank test allowing for two discrete variables is possible as well. If the data is continuous and normal, ‘gaussCItest’ can be selected. A non-parametric, however computationally more demanding, alternative by kernel testing with, e.g., the ‘dHSIC’ package.
We selected the alpha value to be 0.01 as the threshold to compare p-values against. The returned CPDAG is missing the connection between “KINK” and “VLNG” but is otherwise correct. Hence, we were able to nearly recover the correct structure from 20,000 samples. Whether missing an edge or estimating an irrelevant one is worst is use-case specific. Usually however, we recommend overestimating the graph and pruning edges via auxiliary experiments in a later stage. This is specified by the alpha value, where a smaller alphas return denser graphs.
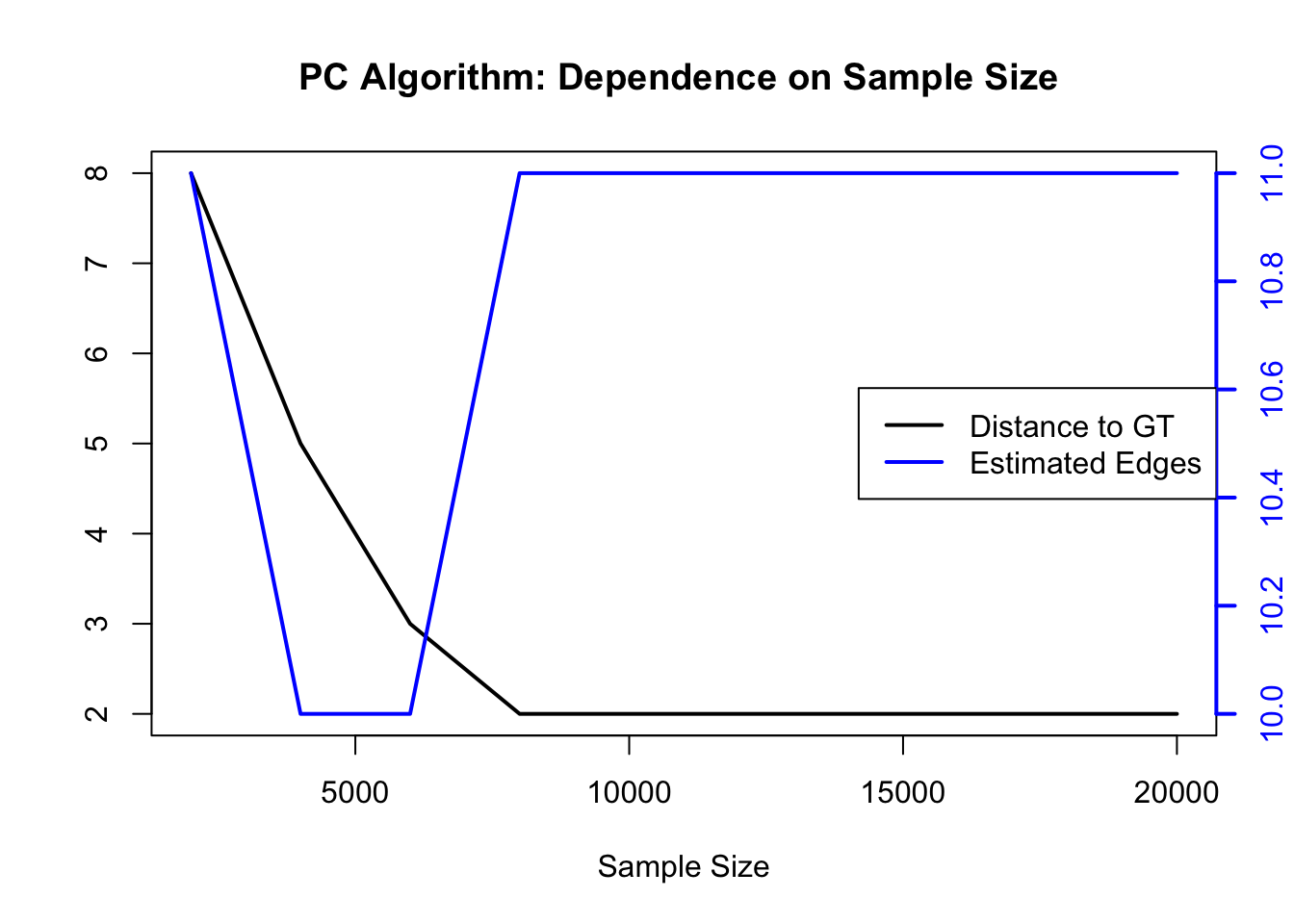
1.5 PC Algorithm: Dependendce on Sample Size
To demonstrate the behavior of increasing testing power, we scale the dataset and visualize the distance of the estimated graph to the ground truth. Note that the lower bound is 1 given by the oracle PC algorithm.
The plot indicates a very good estimation performance from 8,000 samples onwards. When estimating causal effects in a second stage, we recommend data splitting to prevent information leakage.
Finally, the ‘pcalg’ package also supports a ‘skeleton’ function. This skips the second, edge orienting phase and returns an undirected graph. Several applications are solely interested in modeling a joint distribution. By leveraging the obtained independencies, the joint distribution can be expressed and estimated via a product of lower-dimensional distributions decreasing the computational complexity.
# Close environment.libPaths(original_libpaths)
Citing this Notebook
Please cite our community with the following bib item.
@article{Mareis_Haug_Drton_2025,title={MaRDI's Zenodo Community for Graphical Modeling and Causal Inference},volume={2},journal={Proceedings of the Conference on Research Data Infrastructure},author={Mareis, Leopold and Haug, Stephan and Drton, Mathias},year={2025},month={Sep.}}
When using the alarm dataset, please give credit to the original author: Beinlich et al. 1989
Additional Information
License Information: Please follow the above DOI for license information of data and code.
Contact: If you have suggestions, feel free to create an issue or contact the community moderators (mardi’at’statistics.cit.tum.de).