### loading packages
library(bnlearn)
library(qgraph)
library(igraph)
library(pcalg)
library(tidyverse)
library(huge)
library(zen4R)2 ALARM Subgraph Analysis
Setup of the problem
Given a large graph \(G = (V, E)\), where \(V\) represents the set of nodes and \(E\) represents the set of edges, the goal is to select a subgraph \(S = (V_s, E_s)\) from G such that S is a meaningful and informative representation of the original graph \(G\). The subgraph selection problem involves finding an optimal or near-optimal subgraph that satisfies certain criteria or objectives.
In the context of graphical modelling the problem of subgraph selection corresponds to the problem of preserving the conditional independence relationship in the subgraph \(S\) which has to be transferred from the underlying graph \(G\).
Furthermore, it is important to be able to evaluate the results of the structure learning algorithms (learned on the data) taking as a ground truth the selected subgraph.
To read files into R hosted on Zenodo, one can use the zen4R package. One starts by setting up the ZenodoManager
zenodo <- ZenodoManager$new()The ALARM dataset is contained in the Zenodo record 10.5281/zenodo.14793281. The record contains two data objects, which can be listed with the following command.
rec <- zenodo$getRecordByDOI("10.5281/zenodo.14793281")
files <- rec$listFiles(pretty = TRUE)
files filename filesize checksum
alarm.bif alarm.bif 13376 36d1b19ed6a4514e17d2321d1ffb580a
alarm.csv alarm.csv 5661286 0df128ae98e2a899c9de1f27c7c49d4a
download
alarm.bif https://zenodo.org/api/records/14793281/files/alarm.bif/content
alarm.csv https://zenodo.org/api/records/14793281/files/alarm.csv/contentThe file alarm.csv contains the raw data and will be downloaded in the next step using the readr package.
alarm_df <- read_csv(files[2,4])
alarm_df <- alarm_df |>
mutate(across(everything(), ~ case_when(
.x == "FALSE" ~ 0, .x == "TRUE" ~ 1,
.x == "ZERO" ~ 0, .x == "LOW" ~ 1, .x == "NORMAL" ~ 2,
.x == "HIGH" ~ 3, .x == "ONESIDED" ~ 3, .x == "ESOPHAGEAL"~ 4)))
alarm_df# A tibble: 20,000 × 37
CVP PCWP HIST TPR BP CO HRBP HREK HRSA PAP SAO2 FIO2 PRSS
<dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 2 2 0 1 2 3 3 3 3 2 2 1 3
2 2 2 0 2 1 1 3 3 3 2 1 2 3
3 2 3 0 2 2 3 3 3 3 2 1 2 2
4 2 2 0 1 1 3 3 3 3 2 2 2 3
5 2 2 0 1 1 2 3 3 3 2 1 2 1
6 2 2 0 1 2 3 3 3 3 2 1 2 3
7 2 2 0 1 1 3 3 3 3 2 1 1 1
8 2 2 0 2 1 1 3 2 2 1 1 2 3
9 2 1 0 1 1 3 3 3 3 2 1 2 3
10 2 2 0 2 2 3 3 3 3 1 1 2 3
# ℹ 19,990 more rows
# ℹ 24 more variables: ECO2 <dbl>, MINV <dbl>, MVS <dbl>, HYP <dbl>, LVF <dbl>,
# APL <dbl>, ANES <dbl>, PMB <dbl>, INT <dbl>, KINK <dbl>, DISC <dbl>,
# LVV <dbl>, STKV <dbl>, CCHL <dbl>, ERLO <dbl>, HR <dbl>, ERCA <dbl>,
# SHNT <dbl>, PVS <dbl>, ACO2 <dbl>, VALV <dbl>, VLNG <dbl>, VTUB <dbl>,
# VMCH <dbl>The second file in the Zenodo record describes the “true” graph proposed for the ALARM dataset in Scutari and Denis (2021). To read in the bif file, we can use the function read.bif() from the bnlearn package. It creates a bn.fit object, which can be plotted using graphviz.plot().
Scutari, Marco, and Jean-Baptiste Denis. 2021. Bayesian Networks with Examples in R. 2nd ed. Boca Raton: Chapman; Hall.
true_graph <- read.bif("data/download_zenodo/alarm.bif")
graphviz.plot(true_graph, shape = "circle", fontsize = 20)Loading required namespace: Rgraphviz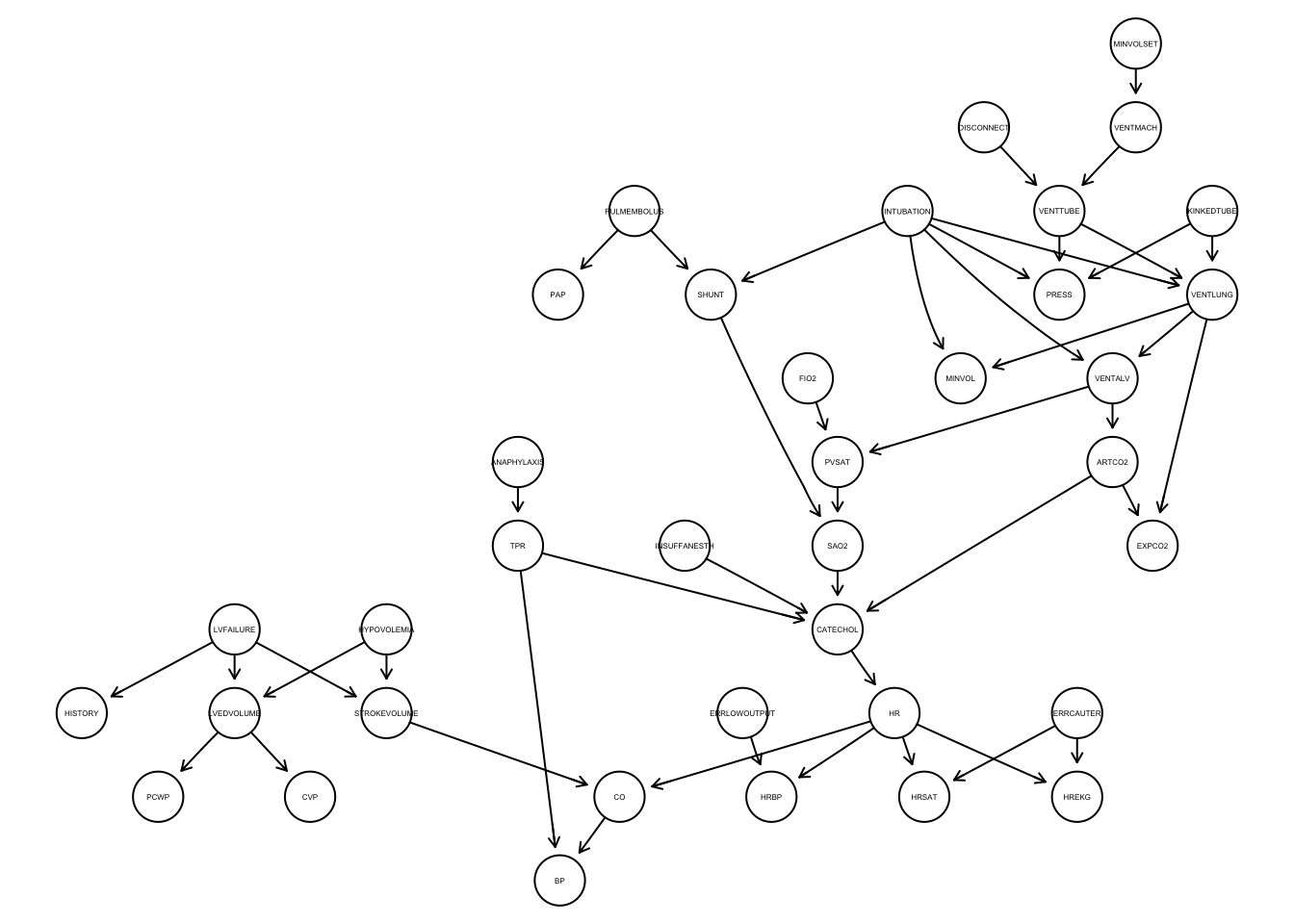
Applying a nonparanormal transformation to standardize the data
alarm_df <- huge.npn(alarm_df)Conducting the nonparanormal (npn) transformation via shrunkun ECDF....done.Defining “true” graph as proposed for the ALARM dataset in bnlearn
# "True" Graph ALARM
dag_alarm = empty.graph(names(alarm))
modelstring(dag_alarm) = paste0("[HIST|LVF][CVP|LVV][PCWP|LVV][HYP][LVV|HYP:LVF]", "[LVF][STKV|HYP:LVF][ERLO][HRBP|ERLO:HR][HREK|ERCA:HR][ERCA][HRSA|ERCA:HR]",
"[ANES][APL][TPR|APL][ECO2|ACO2:VLNG][KINK][MINV|INT:VLNG][FIO2]", "[PVS|FIO2:VALV][SAO2|PVS:SHNT][PAP|PMB][PMB][SHNT|INT:PMB][INT]", "[PRSS|INT:KINK:VTUB][DISC][MVS][VMCH|MVS][VTUB|DISC:VMCH]", "[VLNG|INT:KINK:VTUB][VALV|INT:VLNG][ACO2|VALV][CCHL|ACO2:ANES:SAO2:TPR]",
"[HR|CCHL][CO|HR:STKV][BP|CO:TPR]", sep = "")
qgraph::qgraph(dag_alarm, legend.cex = 0.3,
asize = 2, edge.color="black", vsize= 4)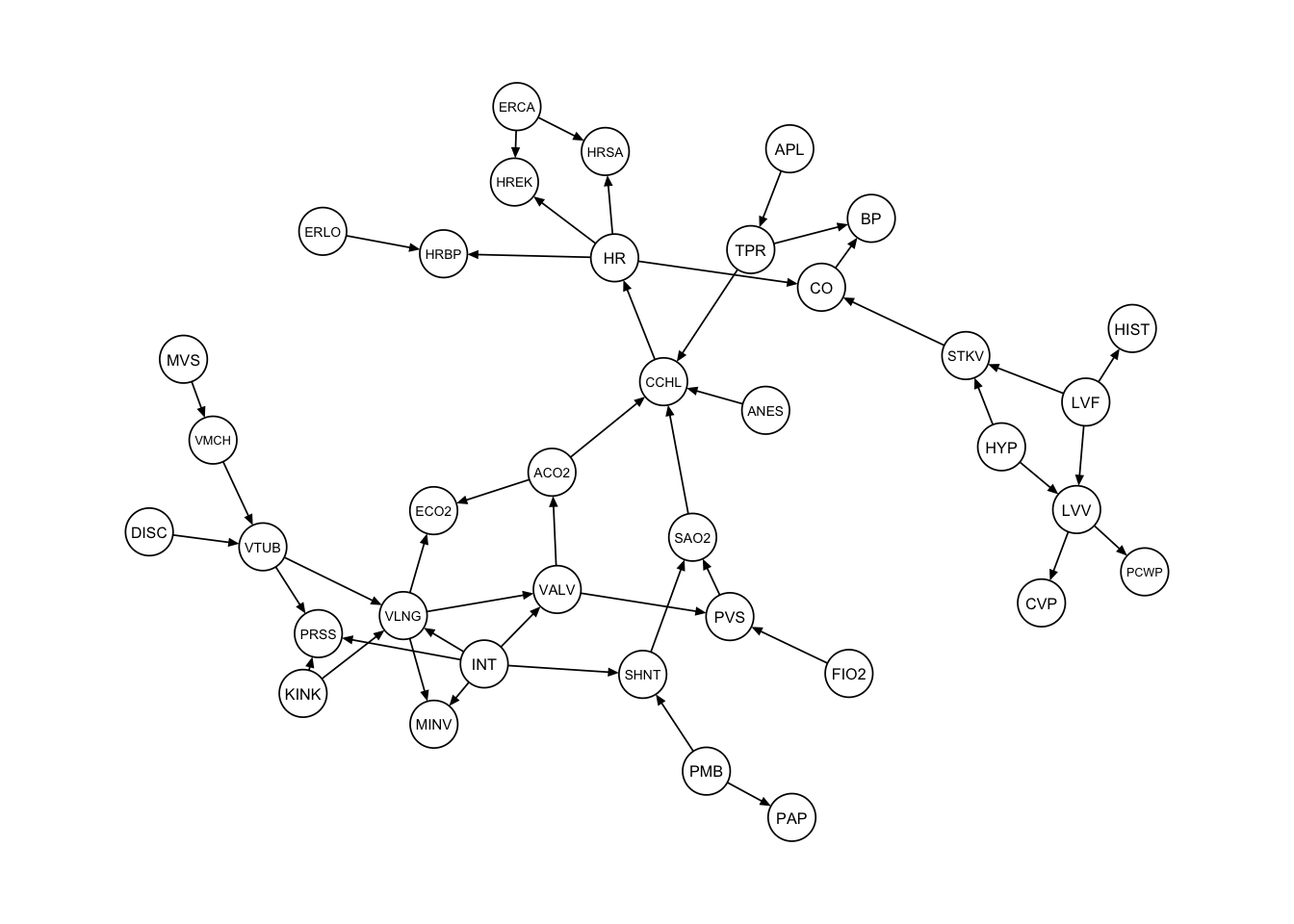
Choosing the nodes to consider in the subgraph selection problem
subgraph_nodes <- c("INT","VALV","LVF","LVV","PCWP","HR","CCHL",
"CVP","HYP","HRSA","ERCA")2.1 Subgraph selection procedures
The first procedure we consider is a simple subsetting of the edges adjacent to the vertices in the subgraph_nodes set. We can accomplish this using the subgraph() function from the bnlearn package.
procedure1 <- bnlearn::subgraph(dag_alarm, subgraph_nodes)
qgraph::qgraph(procedure1, legend.cex = 0.3, asize = 2,
edge.color = "black", vsize = 5)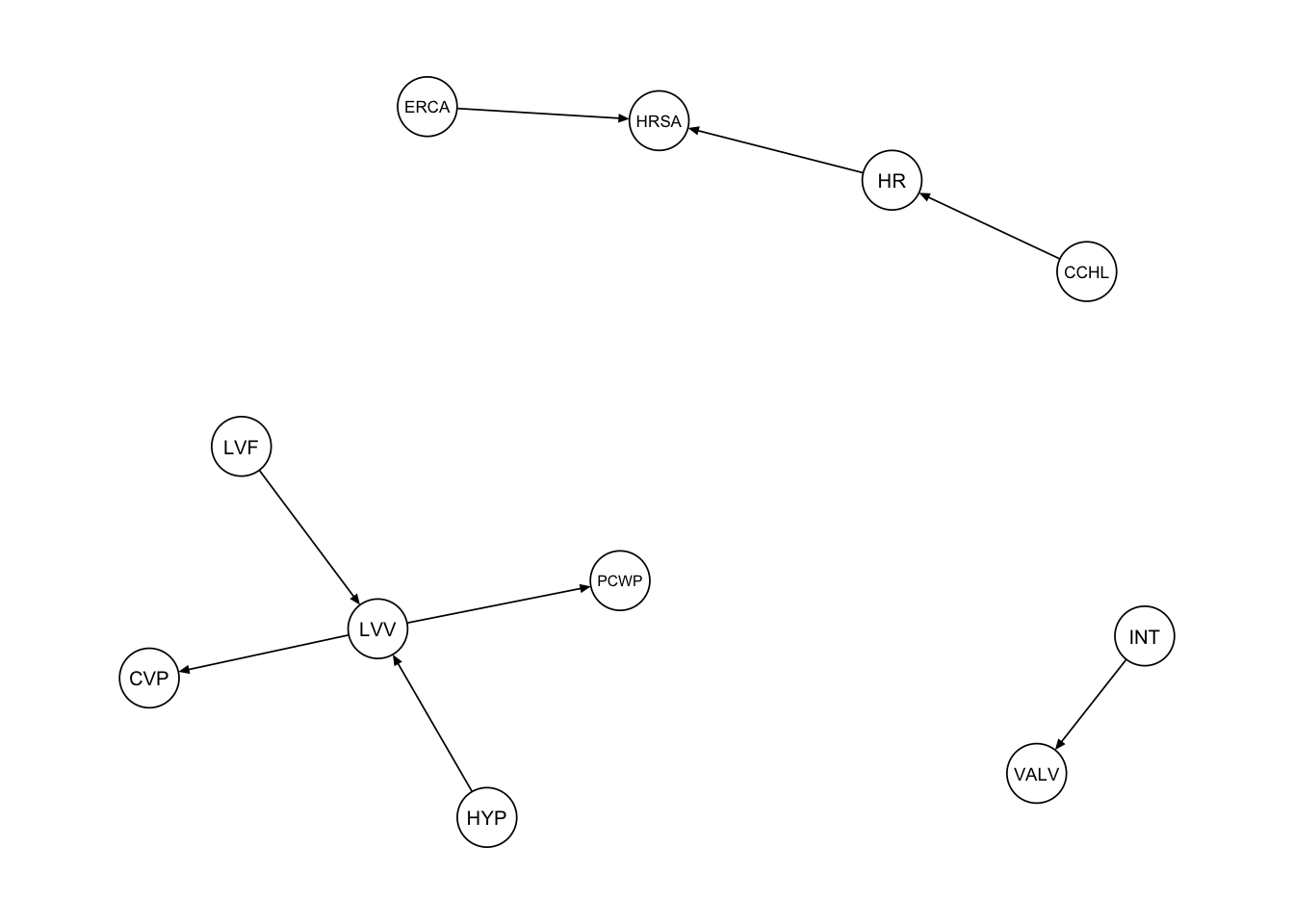
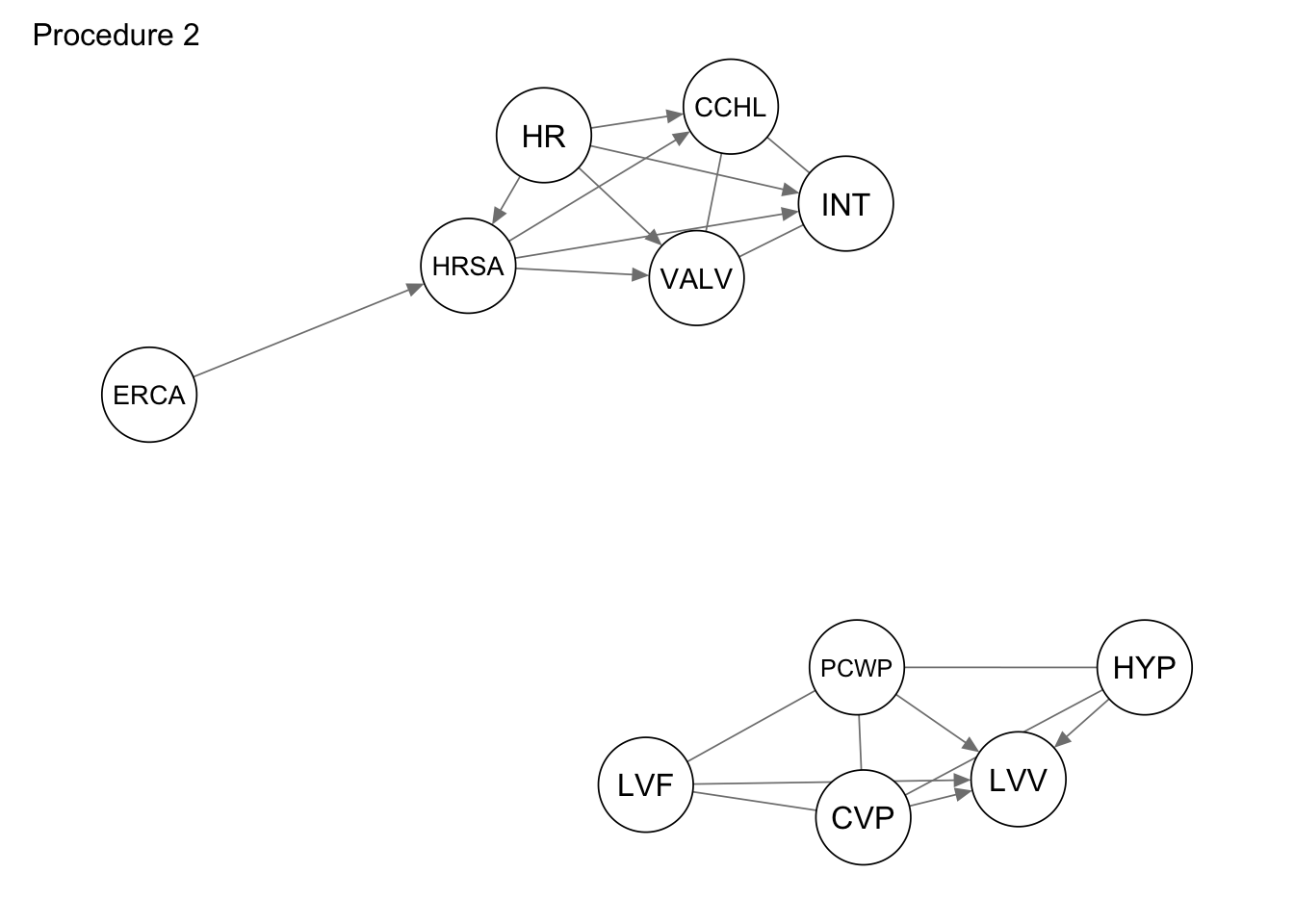
Second procedure selects the subgraph based on the following heuristics:
We are given the ground truth DAG \(G=(V, E)\) with corresponding joint distribution \(\mathsf{P}_V\), and a subset of vertices \(V_{s} \subset V\). The goal is to find the corresponding set of vertices \(E_{s}\) such that the distribution \(\mathsf{P}_{V_s}\) corresponding to \((V_s, E_s)\) does not contradict the structure of the distribution \(P_{V}\).
Let \(G = (V,E)\) be the original directed acyclic graph, and \(P_{V}\) is the joint distribution of random variables from \(V\).
We select two vertices and verify if these vertices are \(d\)-connected given all other vertices in \(V_{s}\). If they are not \(d\)-connected, there is no association (no arrow in any direction). Otherwise, we have an association, but with unknown direction. If one of the directions leads to a cycle in the original graph, we resolve it and keep the other direction, otherwise we keep both directions and then get the CPDAG.
We need to consider all pairs of nodes contained in subgraph_nodes. There exists 2, 55 pairs in total.
The process of checking the \(d\)-connectivity of all pairs of nodes, is implemented in the following function.
extract_subgraph <- function(dag, nodes){
sg <- bnlearn::subgraph(dag,nodes) # procedure 1 (to be discussed)
combinations <- combn(nodes,2) # all combinations of 2 distinct nodes in "nodes"
n <- dim(combinations)[2]
for (i in 1:n){
observed <- nodes[nodes!=combinations[1,i] & nodes!=combinations[2,i]] # V'\{v,w}
if (!is.element(combinations[1,i], nbr(sg, combinations[2,i])) & # check if there exists an edge already
!bnlearn::dsep(dag,combinations[1,i],combinations[2,i])){ ### check if d-connected
sg <- set.edge(sg, from = combinations[1,i], to = combinations[2,i]) ### undirected edge in case d-connected
}
}
return(cpdag(sg)) ### to be discussed: return(cpdag(sg))
}Based on the second procedure we get the following graph.
procedure2 <- extract_subgraph(dag_alarm, subgraph_nodes)
qgraph::qgraph(procedure2, legend.cex = 0.3,
asize=2,edge.color="black", vsize= 5)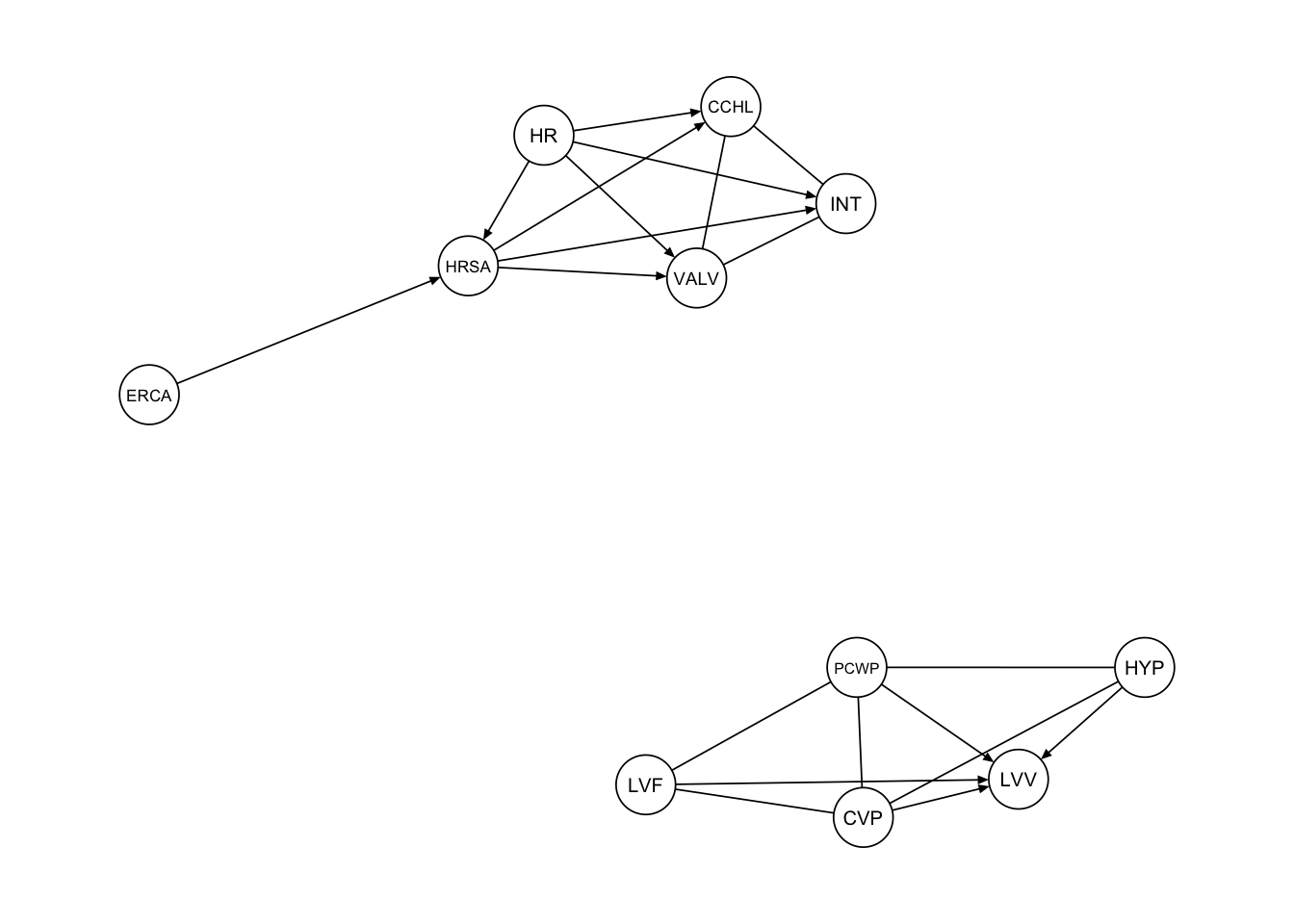
The third procedure creates a partial ancestral graph (PAG) for the observable vertices in the subset-graph with respect to the latent variables in the vertices set \(V \setminus V^{'}\).
PAGs are graphs which are used to represent causal relationships in situations where the exact underlying causal structure is not fully known or observable. In our case we observe the variables in the set \(V^{'}\). Based on the covariance matrix from the observed data in \(V^{'}\) we generate.
Subsetting the dataset according to “subgraph_nodes” selection
alarm_df_subset <- as_tibble(alarm_df) |>
select(all_of(subgraph_nodes))Step 1: Compute the correlation matrix for the observed variables contained in alarm_df_subset.
cor_matrix <- cor(alarm_df_subset)Step 2: Provide necessary information for the algorithm to work on.
indepTest <- pcalg::gaussCItest
suffStat <- list(C = cor_matrix, n = 1000)Step 3: Apply the FCI algorithm to the selected vertices, using the oracle correlation matrix.
normal.pag <- pcalg:: fci(suffStat, indepTest, alpha = 0.05,
labels = subgraph_nodes)Step 4: Plot the resulting PAG (Partial Ancestral Graph).
qgraph(normal.pag@amat, asize=4, edge.color="black", vsize= 5)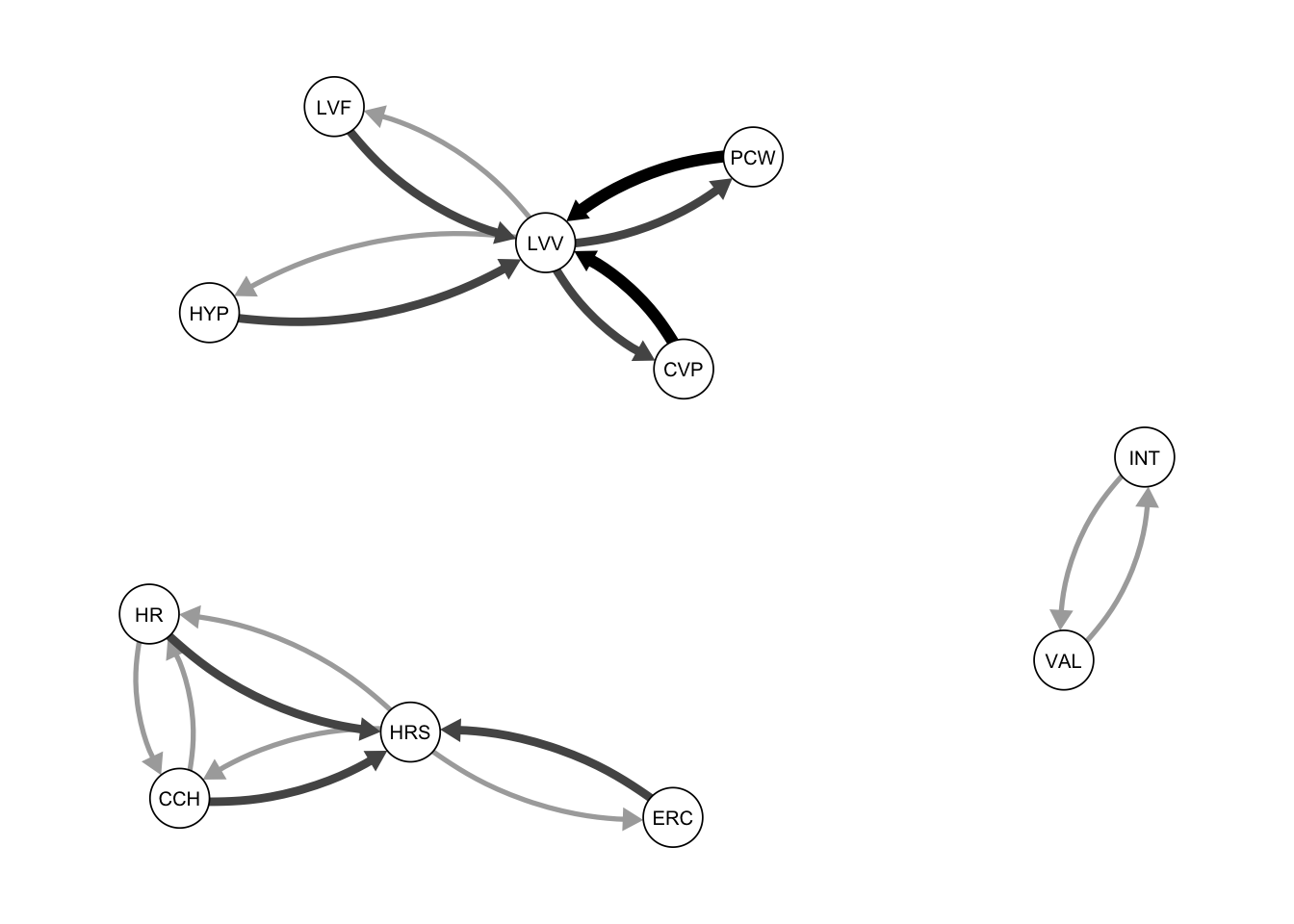
Applying constraint-based algorithms
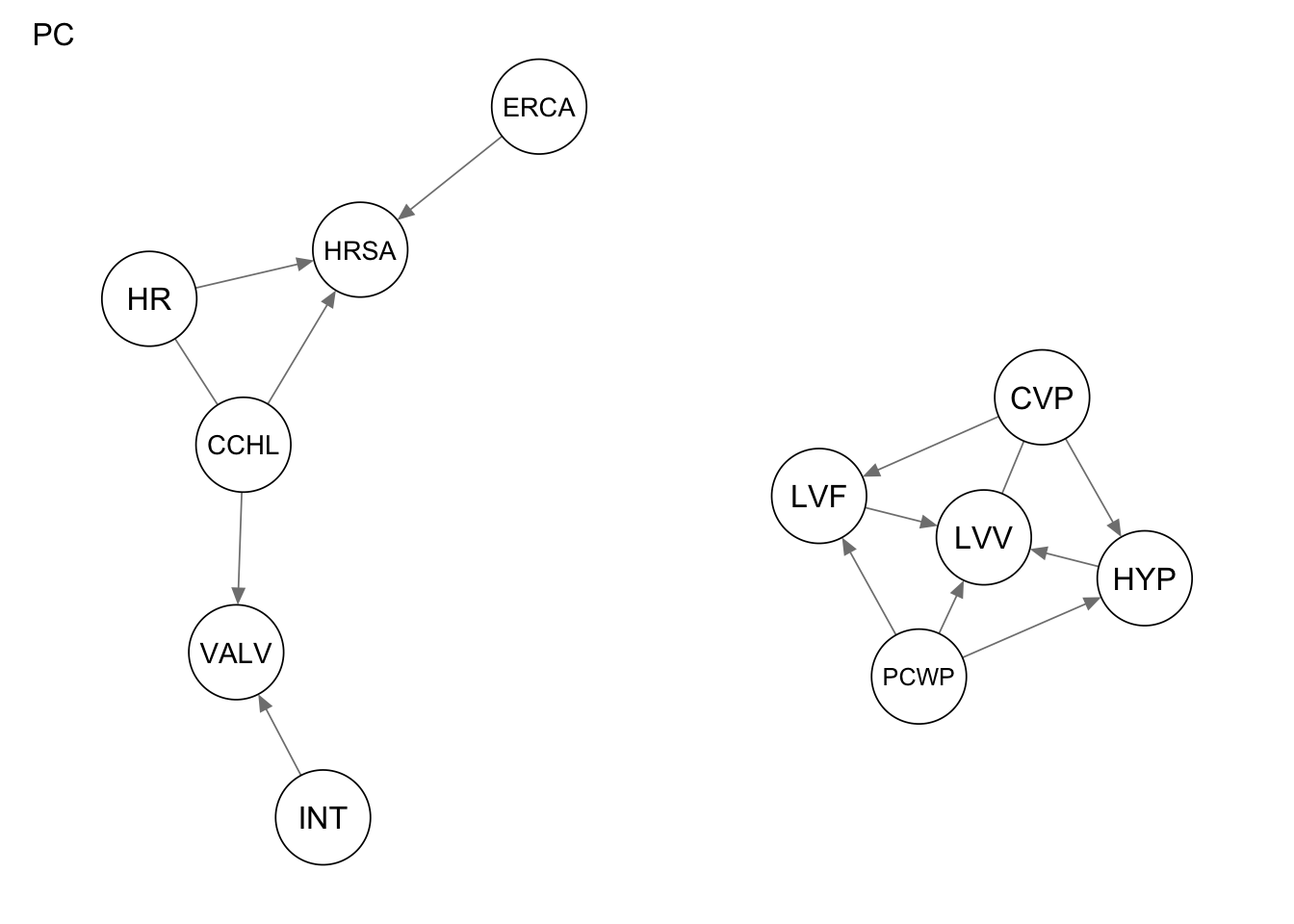
Res_stable <-pc.stable(alarm_df_subset)Warning in vstruct.apply(arcs = arcs, vs = vs, nodes = nodes, debug = debug):
vstructure LVF -> PCWP <- HYP is not applicable, because one or both arcs are
oriented in the opposite direction.Warning in vstruct.apply(arcs = arcs, vs = vs, nodes = nodes, debug = debug):
vstructure LVF -> CVP <- HYP is not applicable, because one or both arcs are
oriented in the opposite direction.Warning in vstruct.apply(arcs = arcs, vs = vs, nodes = nodes, debug = debug):
vstructure VALV -> CCHL <- HRSA is not applicable, because one or both arcs are
oriented in the opposite direction.Res_iamb <- iamb(alarm_df_subset)
Res_gs <- gs(alarm_df_subset)
Res_fiamb <- fast.iamb(alarm_df_subset)
Res_mmpc <- mmpc(alarm_df_subset)Applying score-based algorithms
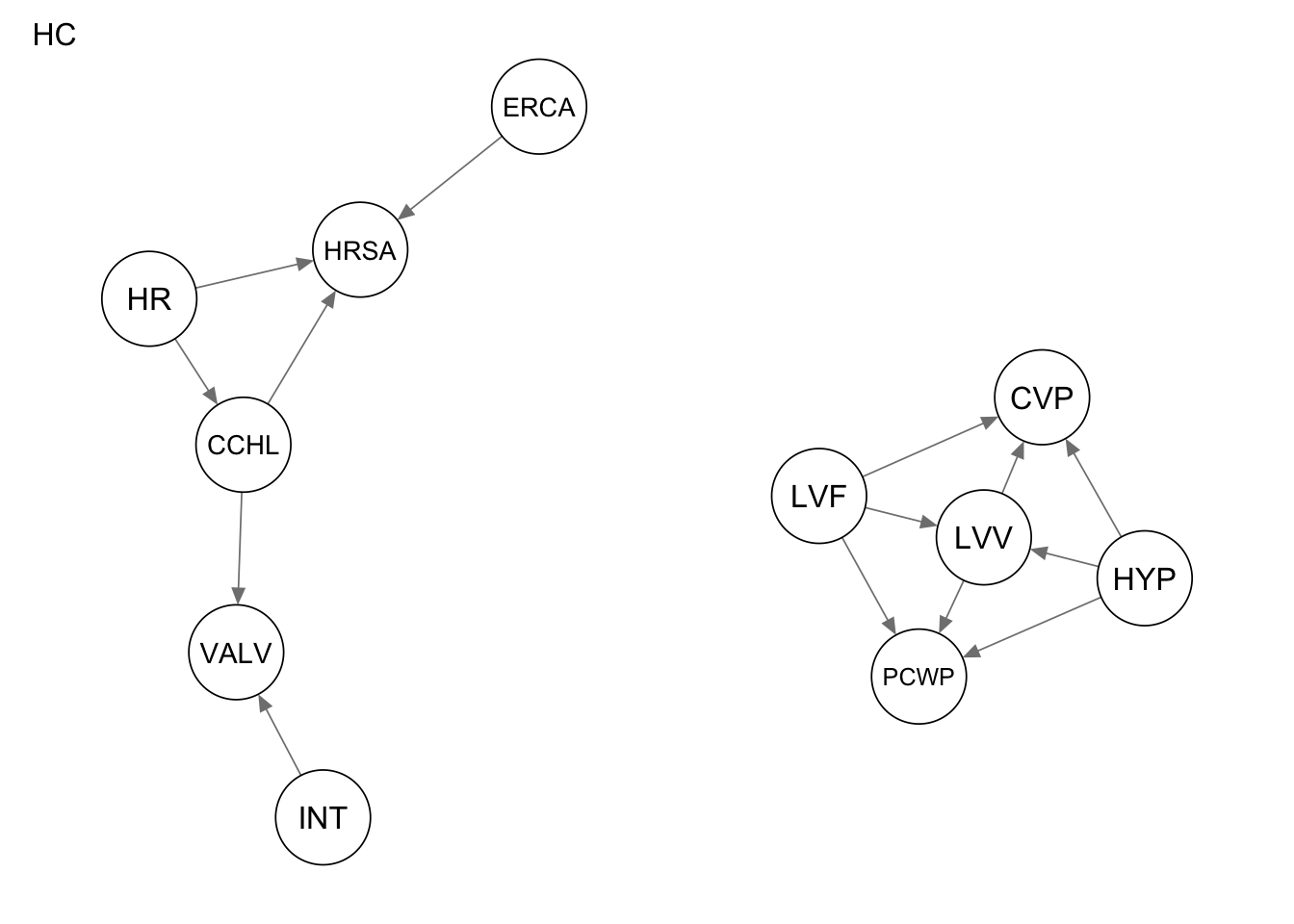
Res_hc <- hc(alarm_df_subset)
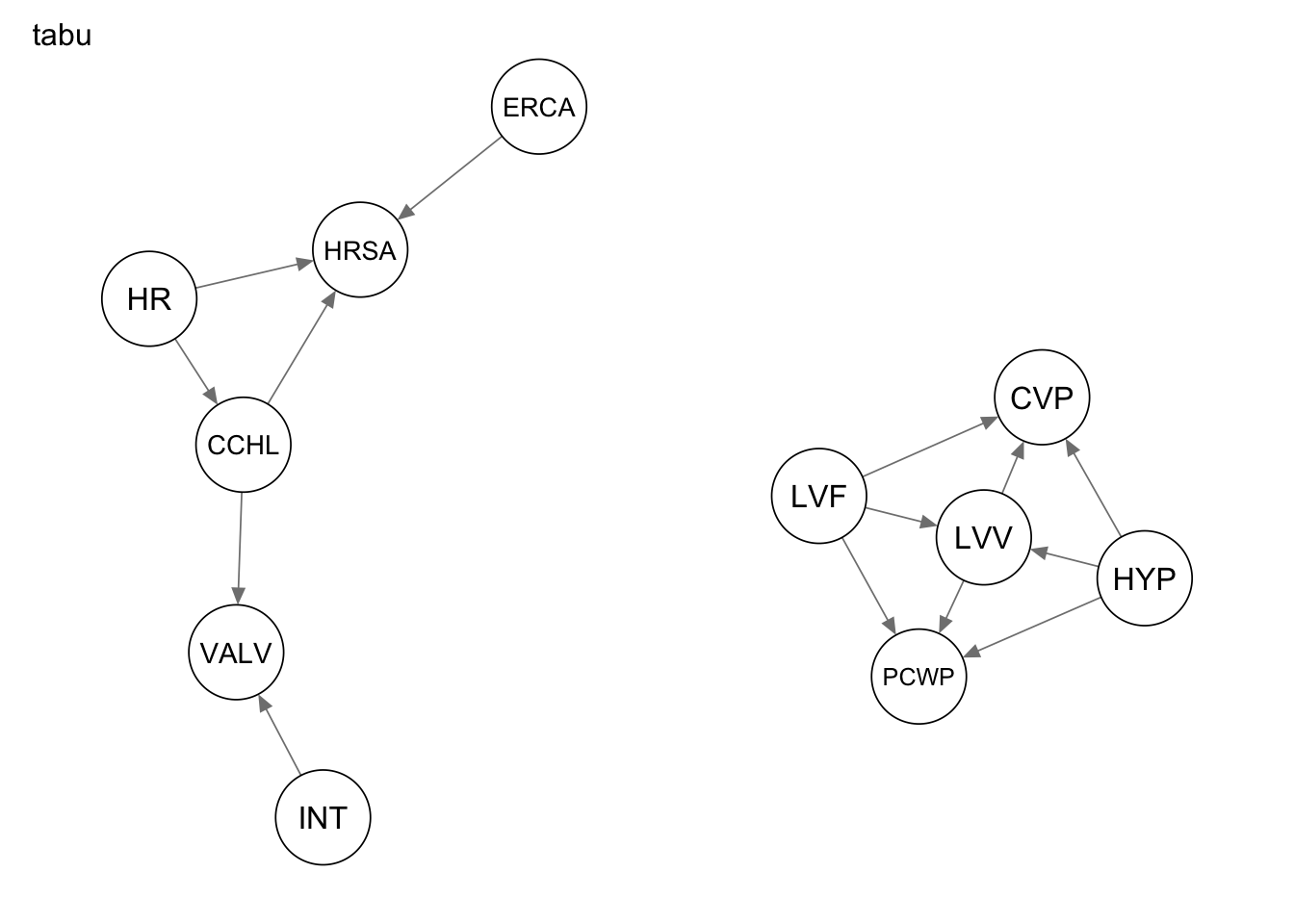
Res_tabu <- tabu(alarm_df_subset)The resulting subgraphs are shown below.
qgraph(procedure1, title = "Procedure 1")
qgraph(procedure2, title = "Procedure 2")
qgraph(Res_stable, title = "PC")
qgraph(Res_iamb, title = "IAMB")
qgraph(Res_gs, title = "GS")
qgraph(Res_fiamb, title = "FIAMB")
qgraph(Res_mmpc, title = "MMPC")
qgraph(Res_hc, title = "HC")
qgraph(Res_tabu, title = "tabu")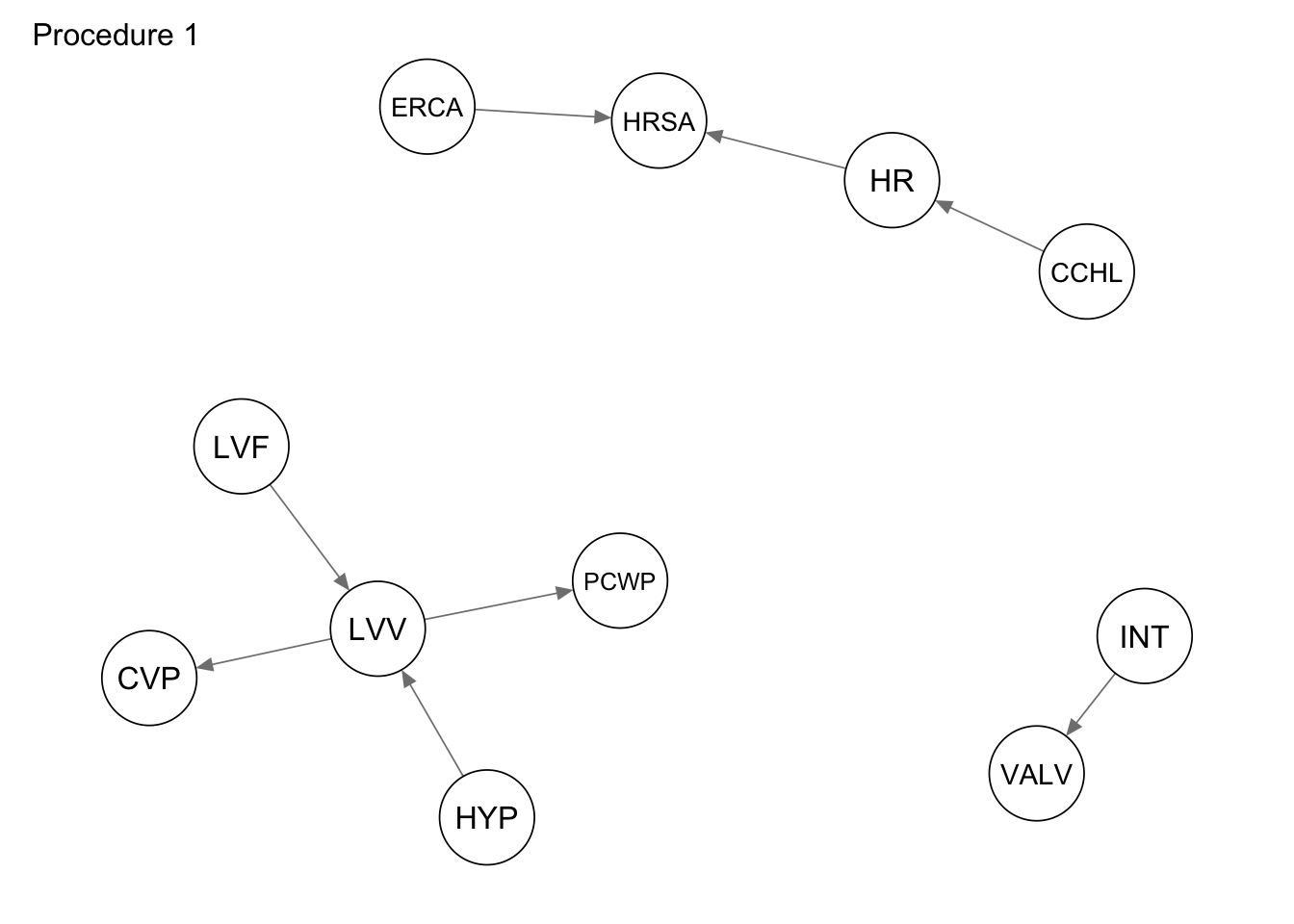
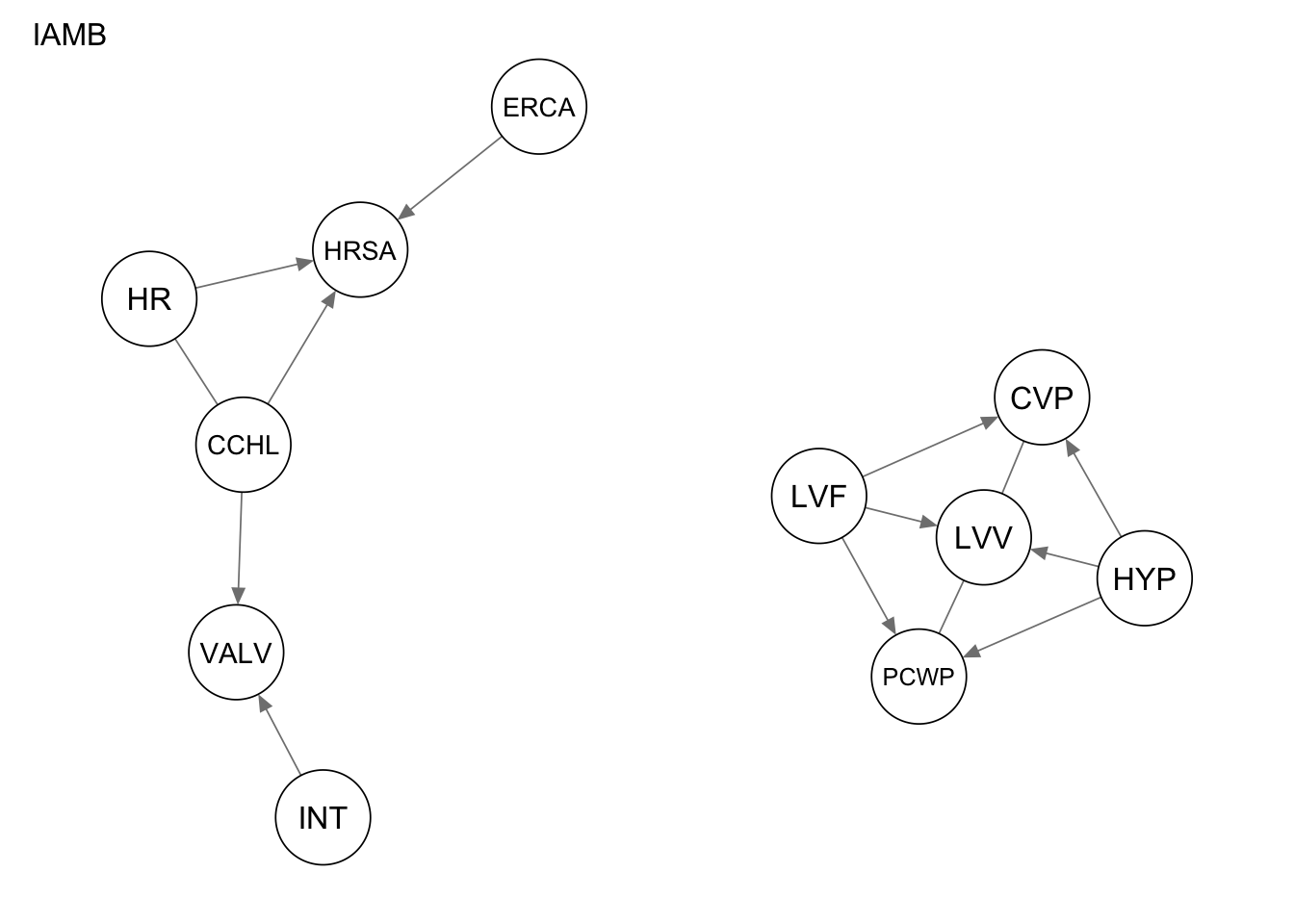
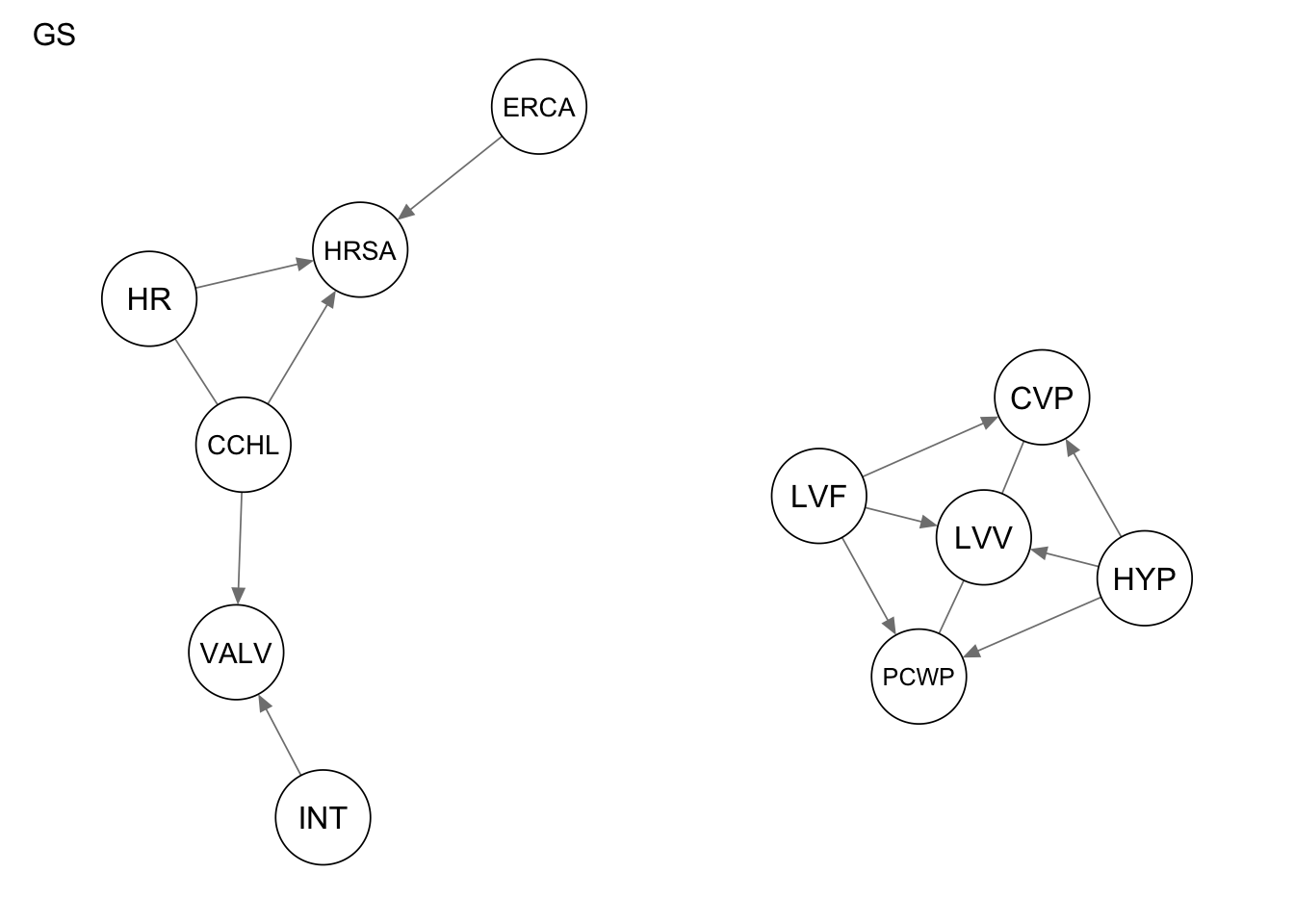
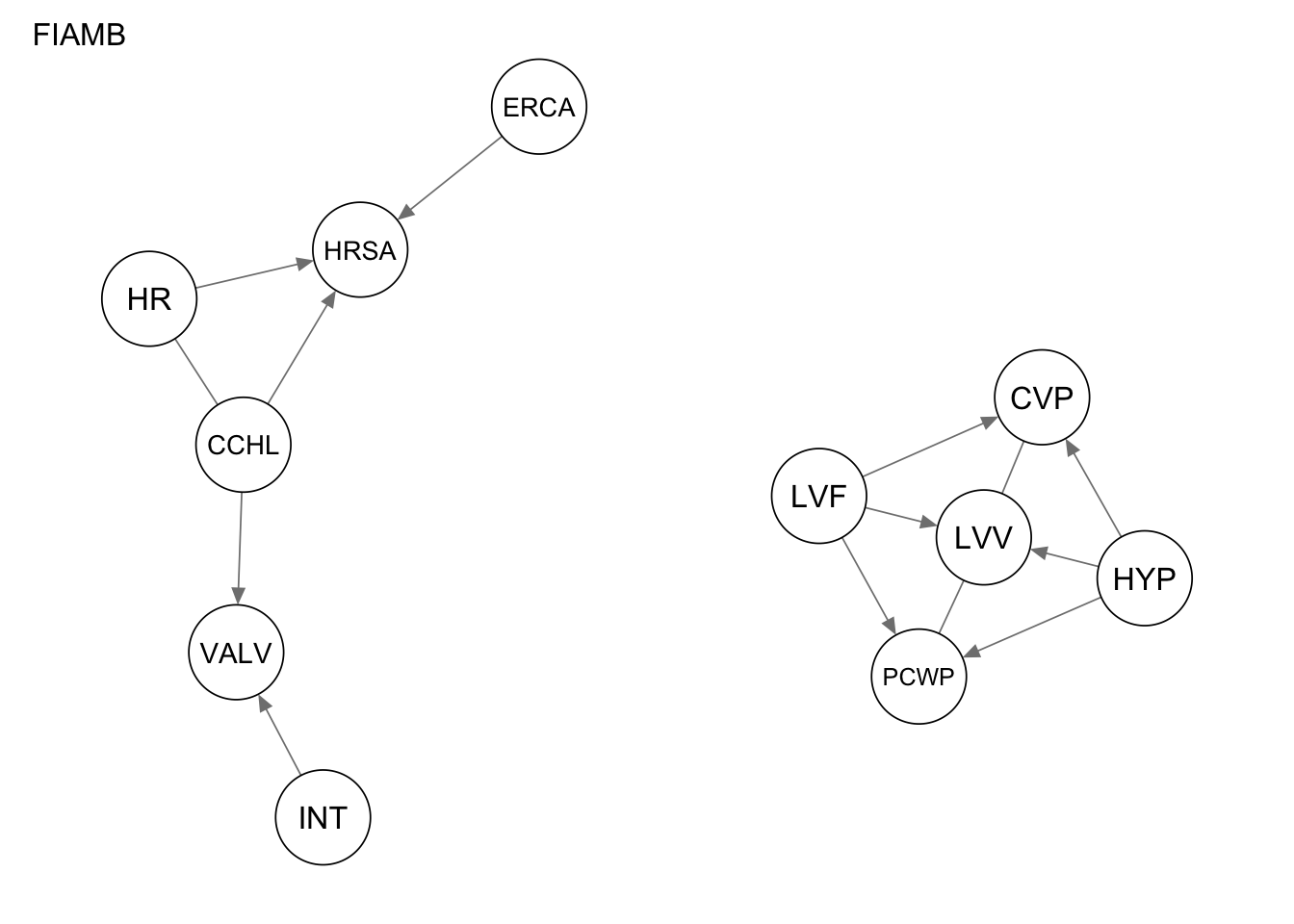
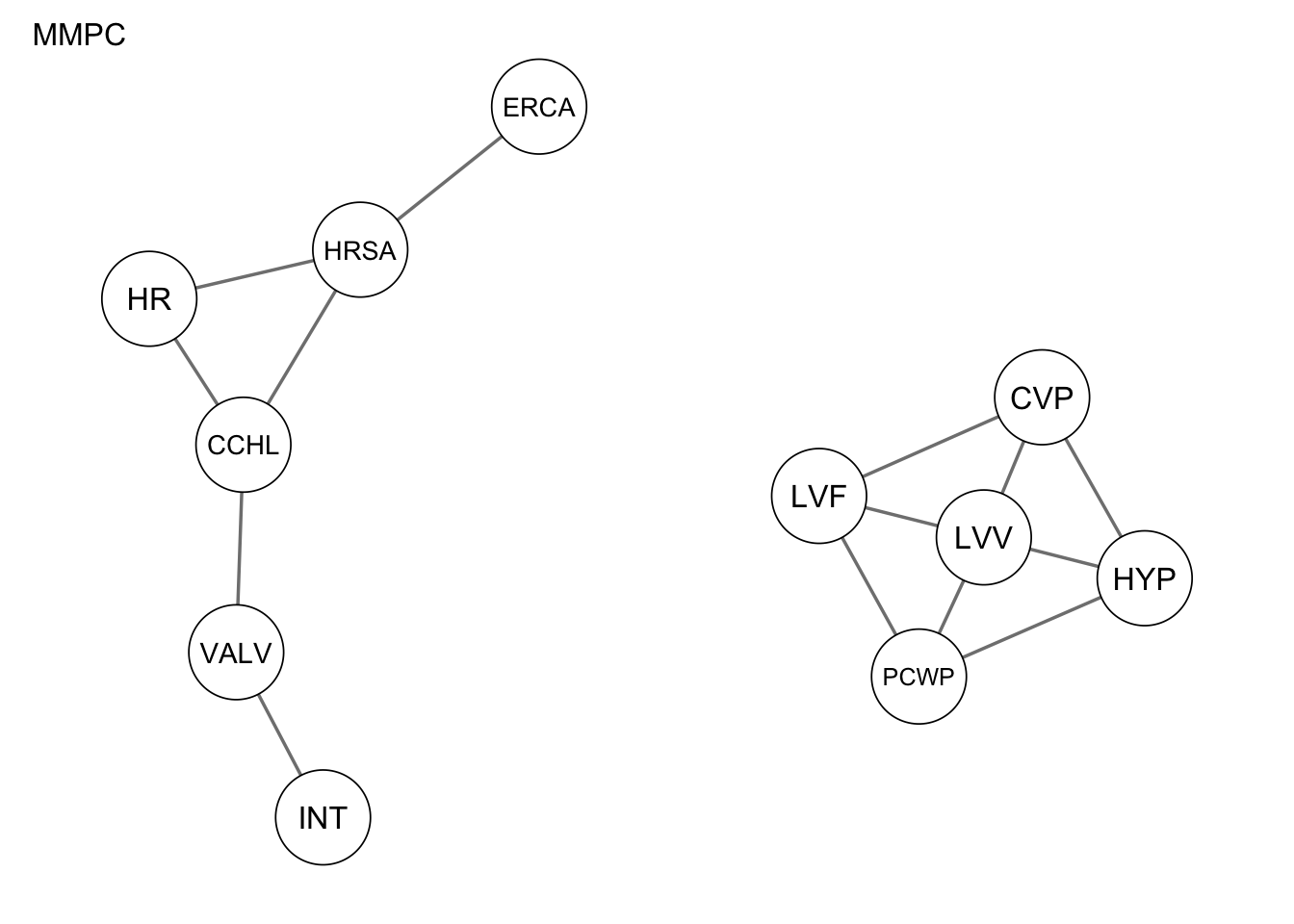
Evaluate the performance by computing the number of true positives, false positives, and false negatives, as well as the structural hamming distance.
measure <- function(estim, true){
result <- matrix(1,4)
com <- bnlearn::compare(estim, true)
shd <- bnlearn::shd(estim,true)
result <- data.frame(
metric = c("true positives","false positives","false negatives","structural hamming distance"),
value = c(com$tp, com$fp, com$fn, shd)
)
return(result)
}Metric evaluation for procedure 1
measure(Res_stable, procedure1) metric value
1 true positives 5
2 false positives 3
3 false negatives 9
4 structural hamming distance 9measure(Res_iamb, procedure1) metric value
1 true positives 5
2 false positives 3
3 false negatives 9
4 structural hamming distance 9measure(Res_gs, procedure1) metric value
1 true positives 5
2 false positives 3
3 false negatives 9
4 structural hamming distance 9measure(Res_fiamb, procedure1) metric value
1 true positives 5
2 false positives 3
3 false negatives 9
4 structural hamming distance 9measure(Res_mmpc, procedure1) metric value
1 true positives 0
2 false positives 8
3 false negatives 14
4 structural hamming distance 12measure(Res_hc, procedure1) metric value
1 true positives 7
2 false positives 1
3 false negatives 7
4 structural hamming distance 9measure(Res_tabu, procedure1) metric value
1 true positives 7
2 false positives 1
3 false negatives 7
4 structural hamming distance 9Metric evaluation for procedure 2
measure(Res_stable, procedure2) metric value
1 true positives 5
2 false positives 15
3 false negatives 9
4 structural hamming distance 15measure(Res_iamb, procedure2) metric value
1 true positives 4
2 false positives 16
3 false negatives 10
4 structural hamming distance 16measure(Res_gs, procedure2) metric value
1 true positives 4
2 false positives 16
3 false negatives 10
4 structural hamming distance 16measure(Res_fiamb, procedure2) metric value
1 true positives 4
2 false positives 16
3 false negatives 10
4 structural hamming distance 16measure(Res_mmpc, procedure2) metric value
1 true positives 6
2 false positives 14
3 false negatives 8
4 structural hamming distance 14measure(Res_hc, procedure2) metric value
1 true positives 5
2 false positives 15
3 false negatives 9
4 structural hamming distance 16measure(Res_tabu, procedure2) metric value
1 true positives 5
2 false positives 15
3 false negatives 9
4 structural hamming distance 16