Contributing to GMCI
Overview
The GMCI initiative relies on submissions from the research community to grow and remain current. Two types of contributions are accepted: datasets and analysis notebooks. Both are archived on Zenodo with a persistent digital object identifier and become part of the moderated GMCI Zenodo community. All submissions are reviewed by the GMCI moderators, who may request revisions and are available to assist contributors throughout the process. There are no costs associated with submission or archiving.
Intellectual ownership of submitted content remains with the authors following acceptance. Git repositories hosting analysis notebooks are integrated as submodules of the GMCI repository, and Zenodo records become part of the GMCI community; neither is transferred in ownership.
Submitting a Dataset
Account creation
A Zenodo account is required to submit. Accounts can be created directly or linked via GitHub, ORCID, or OpenAIRE.
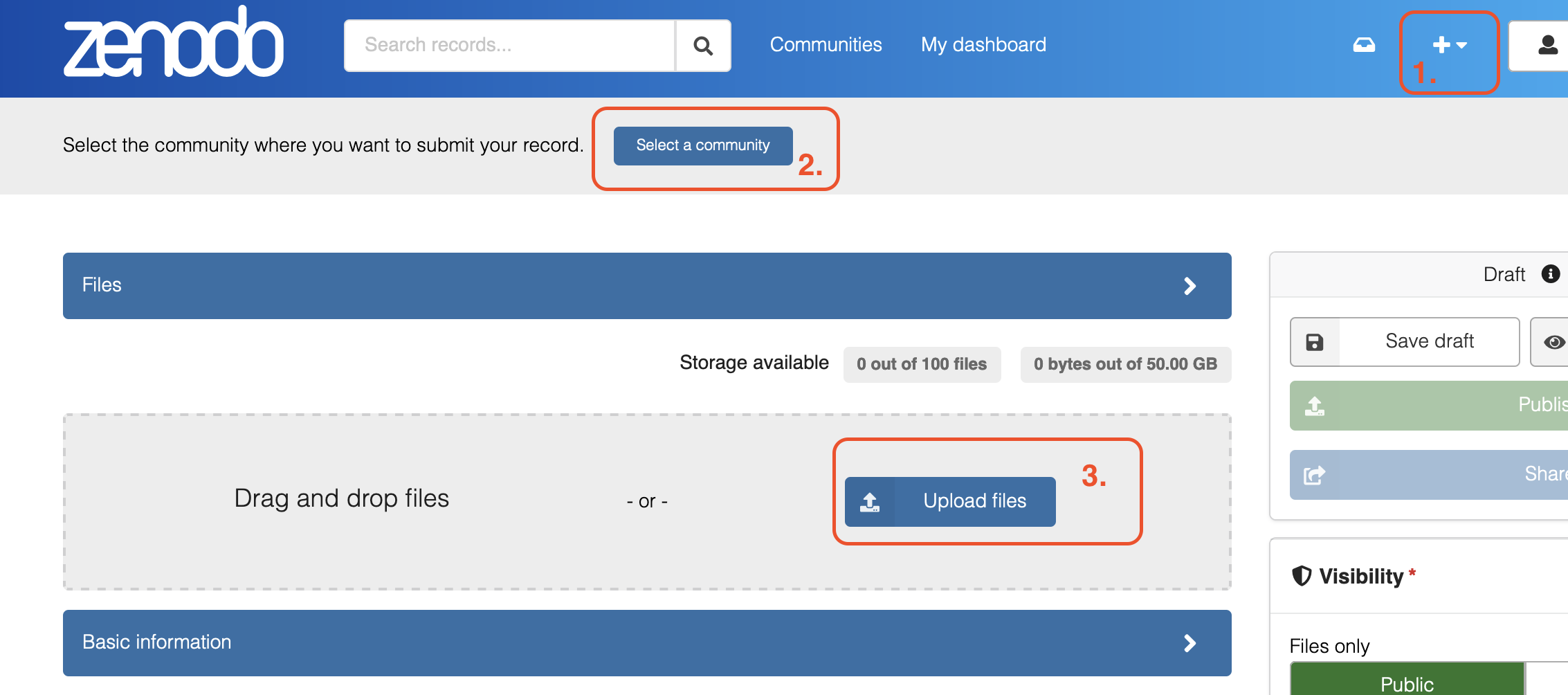
Creating a record
To create a new record, click the + button in the Zenodo interface and select the Graphical Modelling and Causal Inference community at the time of upload.
File formats
A single dataset should be uploaded as a .csv file. A collection of datasets should be compressed as a .zip archive. Auxiliary files, including graph structure specifications, ground truth files, licences, and extended documentation, should be uploaded as separate files within the same record.
Required record description
The description field of the Zenodo record must follow the structured format given below. Thorough completion of this metadata is essential for making the submission findable and reusable by the community.
A description of the dataset or dataset collection.
Task: A description of the causal or statistical task the dataset is intended to address.
Summary:
Size of dataset: Nr. of samples x Nr. of dimensions
Task: Causal Discovery Problem / Causal Inference Problem
Data Type: Continuous Data / Mixed Data / Discrete Data / Binary Data / Categorical Data
Dataset Scope: Collection of Datasets / Standalone Dataset
Ground Truth: Known Graph / Partial Graph / Unknown Graph
Temporal Structure: Static Data / Time Series Data
License: CC0 / CC BY / CC BY-NC / …
Missing Values: Existing Missing Values / No Missing Values
Missingness Statement: (if applicable)
Collection: # If applicable.
Dataset1: Description
Dataset2: Description
Features:
Feature1: Description
Feature2: Description
Files:
File1: Description
File2: Description
License:
File1: License
File2: License
Well-documented reference submissions that may serve as models are the ALARM (A Logical Alarm Reduction Mechanism) dataset and the Sachs: Protein and Phospholipid Expressions dataset collection.
Submitting an Analysis Notebook
Preparing the repository
Notebook submissions must be prepared from the GMCI notebook template. The primary analysis file is notebook.qmd, which should be completed in accordance with the template’s structure. A preview image named gallery_picture.png must be included in the repository root for display in the notebook library.
Connecting the repository to Zenodo
After preparing the repository, connect it to Zenodo via the GitHub integration. Once connected, creating a release in GitHub will automatically generate a Zenodo record containing a zipped copy of the repository and a unique DOI. Because the entire repository is archived, its contents should be kept to the files necessary for the analysis.
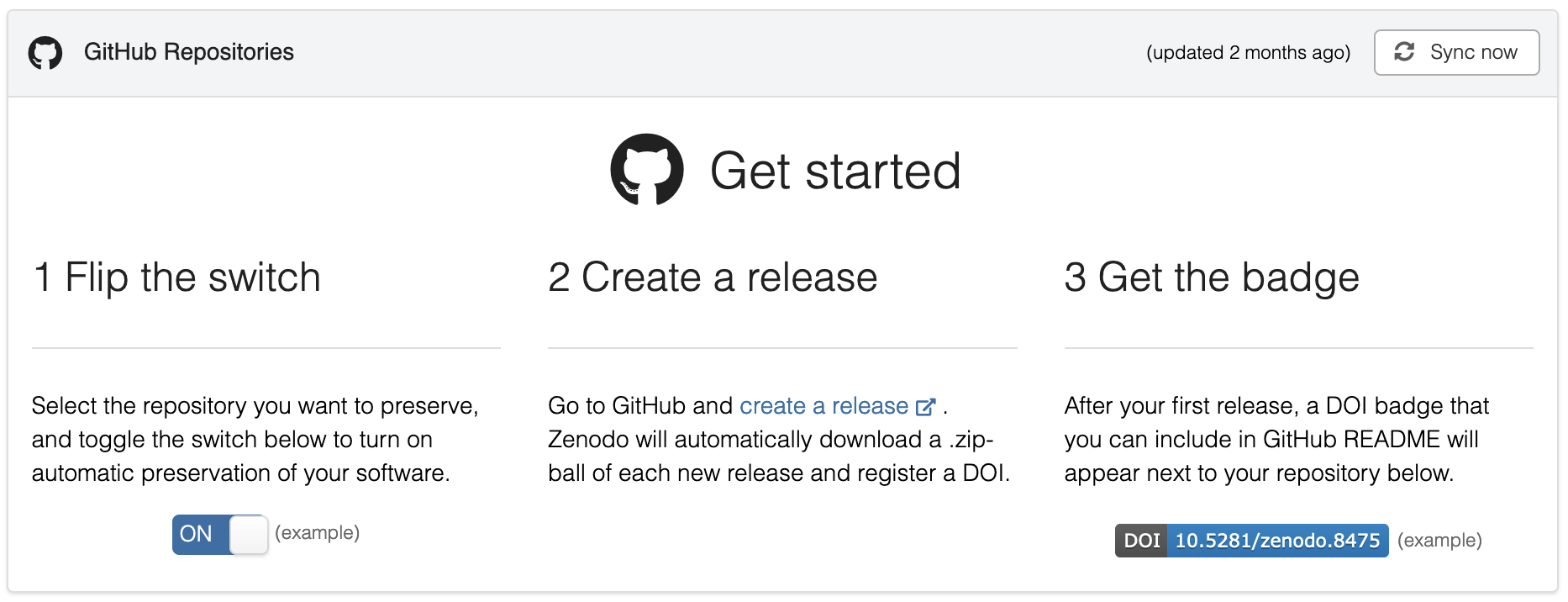
Submitting to the GMCI community
The Zenodo record created by the first release should be submitted to the GMCI community by editing the record page. Although the record description is populated from the GitHub release notes, all metadata fields can be edited manually after creation. Authors are encouraged to add supplementary information such as associated publication references, linked dataset records, or R or Python package identifiers.
Notifying the GMCI team
The GMCI moderators must be notified when a new release is published, as new releases automatically generate a new version of the Zenodo record but do not trigger re-rendering of the notebook on this website. The website must be updated manually by the moderators.
A well-documented reference implementation is the PC Algorithm for Causal Discovery.
Review Process
Upon submission, the GMCI moderators will assess whether the contribution meets the requirements described above, and may request revisions before acceptance. Moderators will assist with questions that arise during the process. Once a submission is accepted, datasets appear in the GMCI Zenodo community and are listed in the dataset collection on this website; accepted notebook repositories are added as git submodules, and the rendered analysis is featured in the Notebook Library.
On the FAIR Principles
A central objective of the GMCI initiative is to ensure that submitted resources conform to the FAIR principles for scientific data management (Wilkinson et al. 2016). Findability is achieved through persistent DOIs and structured, searchable metadata on Zenodo. Accessibility requires that resources be openly available under clearly stated licences. Interoperability is promoted by the use of standardised formats and metadata schemas. Reusability demands that design decisions, provenance, and licensing be communicated transparently. Contributors are asked to provide as complete metadata as the nature of their submission allows. The value of the GMCI collection depends directly on the quality and completeness of this information.
About Zenodo
Zenodo is an open-access digital repository hosted by CERN, providing long-term storage with persistent DOIs suitable for citation in academic publications. Several properties of the platform are particularly relevant for GMCI contributors. Records and their associated data files are permanent and cannot be deleted except in exceptional circumstances. Metadata fields, including descriptions, licences, and linked references, can be modified after the initial record creation. Publishing a new release of a connected GitHub repository automatically creates a new version of the Zenodo record, while all prior versions remain accessible with their original DOIs. Authors who wish to explore the submission process before committing to a permanent record may do so using Zenodo Sandbox, which replicates the full functionality of the platform without creating permanent digital objects.